4641-project
Introduction/Background:
League of Legends is a 5v5 multiplayer game where two teams of 5 champions compete against each other to destroy the enemy nexus. With over 170 unique champions, each possessing distinct abilities, strengths, and weaknesses, the strategic depth of team composition is immense. Before a match even begins, critical decisions are made during the champion selection phase that can significantly influence the game’s outcome.
Existing work in this field revolves around computing win probability over the course of the match based on real time data (e.g. the gold difference at a specific time) [1] [2]. However, being able to predict game outcomes based solely on pregame data, such as player and champion trends, can inform players of how to approach the match to maximize chances of winning. In addition, the ability to predict game outcomes can be used to analyze the fairness of matchmaking and inform better matchmaking algorithms.
Definitions
League is a complicated game, so a brief overview of League terminology may prove to be helpful to the uninformed.
Champions: Playable character that each player selects. Each champion has unique abilities, attacks, stats, etc.
Roles: The position that a player plays. Each team has a Top Laner, a Jungler, a Mid Laner, a Bot Laner (also known as the AD Carry), and a Support.
Summoner Spells: Special abilities that can be activated in game. These are chosen before the game starts, and any summoner spell can be selected with any champion.
Runes: Customizable set of passive bonuses/perks. Similarly to summoner spells, runes are chosen before the game starts and can be used with any champion.
Matchups: Refers to a 1v1 between two champions in a specific role. For example, Garen vs Darius in the Top Lane.
Gold: An in game currency used by each team to buy upgrades, earned by completing in game objectives. Having more gold than the enemy team is highly correlated with winning.
Problem Definition
Given only pre-game information available at match start, namely the Champions, Summoner Spells, Runes, and Roles of each player as well as matchup data, our goal is to predict the outcome for a given match. Formally, we want to model \(\mathbb{P}(\text{blue win} \mid \text{pre-game features, match duration} \geq t)\)for some time \(t\). It suffices to only model blue win since League is zero sum.
Data Collection and Preprocessing
The Riot API was used to gather data for the model. We chose to select all Ranked Solo/Duo games for players in Emerald or higher within the past month, in the North American, Europe West, and Korean servers. We chose Ranked Emerald+ because lower tier ranked games tend to be filled with individual player mistakes and non sensible gameplay, which overall reduces the impact of the champion draft on outcome. Higher ranked players tend to be closer in skill and also tend to play more consistently, meaning that champion draft has a much higher impact. In terms of server choice, North America, Europe West, and Korea are widely considered to contain the best players. Additionally, each server API endpoint rate limits independently, so using 3 servers allows us to make 3x more API calls.
Unfortunately, the Riot API does not provide a way to get a list of matches, rather it only provides a way to get the matches for a specific player. Thus, gathering the data was done in two parts: match seeding and match cleaning.
Part 1 (Match Seeding)
- Query the Riot API for a list of players
- For each player, get their 20 most recent matches (returned as IDs), store them in the database, and add the matches to a queue.
- While the queue is not empty,
- Pop a matchid from the queue,
- Call the Riot API to get the corresponding match data for that match.
- For each of the 10 players in that match, add their 20 most recent matches to the database and the queue.
Since the queue never becomes empty due to the high branching factor, this program is manually stopped by the user once a sufficient number of matches have been seeded.
Part 2 (Match Cleaning)
- Query the database for uncleaned match_ids
- For each match_id, query the Riot API for
- The match data, from the
MATCH-V5endpoint - The gold timeline data, from the
MATCH-V5/TIMELINEendpoint
- The match data, from the
- Clean and extract the useful parts of the data and store in the database.
- Repeat steps 1-3 until all seeded matches have been processed.
The Riot API has a rate limit of about 1 request a second. Since each player has 20 recent matches, the seeder adds about 20 matches to the database with 1 API request and was thus able to process 1.2 million matches in a few hours. For the match cleaner, each match required=s 2 distinct API calls, so processing 1.2 million matches requires 667 total hours. This was too long, so we utilized AWS to implement a cloud based architecture to run the match cleaner concurrently.
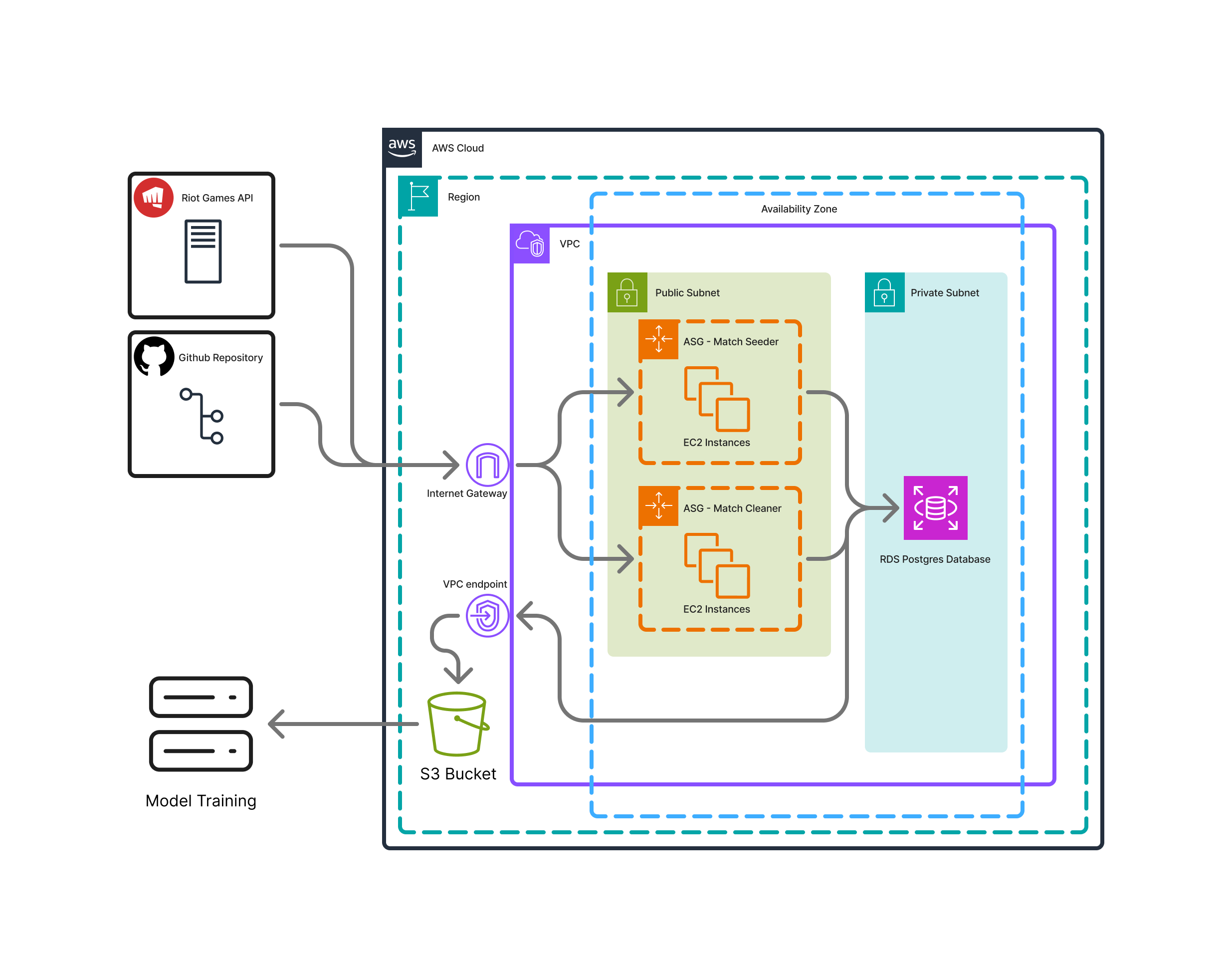
The Match cleaners were run concurrently on AWS EC2 instances, and the data was written to PostgreSQL database hosted on RDS. Once all the matches were cleaned, the data was dumped to an S3 bucket to be distributed to local computers for training. Using 6 API keys provided by group members, we were able to clean all 1.2 million matches in just over 3 days.
Additionally, matchup data was tracked for each of the 1.2 million matches. For each champion vs. champion in a specific lane, the total number of games as well as the number of wins was recorded to eventually calculate the matchup winrate. As these winrate statistics were used in training the model, we realized we had to create an additional, separate dataset that did not contribute to these statistics for training. Thus an additional testing/validation dataset of about 100k matches was generated.
Some data cleaning was also performed on the dataset. Games longer than 60 minutes were removed, as not only are these games extremely rare, these games are typically a result of some form of match stalling or griefing. Under normal circumstances, League of Legends games rarely last longer than 45 minutes, so we made the choice to purge 60 minute+ games to make implementation easier. Just over 200 games out of 1.2 million were longer than 60 minutes, or about 0.01%. Additionally, some games were missing information, which was most likely Riot’s fault. Only 3 games were missing information, and they were removed.
An Interesting Note about the Dataset
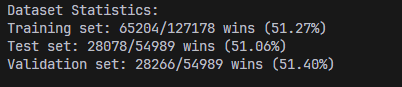
Both datasets had a higher winrate for the blue team. This is not due to errors in the data collection process; rather, due to various game mechanics (such as the location of neutral objectives), the blue side team has a slight in game advantage that is reflected in the winrate. Dealing with this imbalance proved to be a challenge in developing models
Supervised ML Algorithms/Models Implemented
MLP
We iterated upon our previously implemented MLP model, trying out many different configurations and ideas. The base configuration code is below.
def __init__(self):
super().__init__()
if USE_ONEHOT:
self.embedding = OneHot(use_matchups=USE_MATCHUPS, only_champs=ONLY_CHAMPS)
else:
self.embedding = Embedding()
input_dim = self.embedding.input_dim
self.hidden = nn.Sequential(
nn.Linear(input_dim, 512),
nn.ReLU(),
nn.Dropout(0.3),
nn.Linear(512, 256),
nn.ReLU(),
nn.Dropout(0.2),
nn.Linear(256, 256),
nn.ReLU(),
nn.Dropout(0.1),
nn.Linear(256, 256),
nn.ReLU(),
nn.Dropout(0.1),
)
self.output_1 = nn.Linear(256, 60)
self.output_2 = nn.Linear(256, 1)
def forward(self, champions, keystones, spells, roles, matchups=None):
x = self.embedding(champions, matchups)
x = self.hidden(x)
gold_output = self.output_1(x)
win_output = self.output_2(x)
return gold_output, win_output
The goal of this specific layer configuration is to be complex enough to understand the relationships between features, while also not overfitting. The model takes in features from the embedding layer, which can be either one-hot encoded or embedded, and passes them through a series of fully connected layers with ReLU activations and dropout for regularization. The output consists of two parts: a gold graph prediction (60 time buckets) and a win prediction (binary 0 or 1).
Embedding Layer
Initially, we tried using an embedding layer initialized with nn.Embedding to convert champion ids to vectors in a latent space. However, after testing with various hyperparameters and model sizes, we could not get good results. Visualizing the embeddings after training, we find that they are normally distributed which does not seem reasonable—a uniform distribution is to be expected.
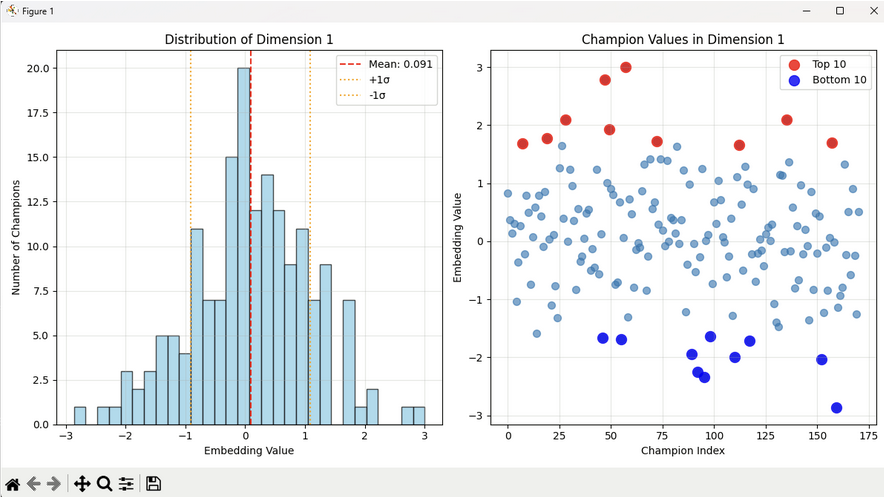
In the embedding layer, internal ids for champions, runes, spells, and roles are mapped to a latent space with nn.Embedding. This is initially randomized and is learned through training. The embedding layers are as follows:
self.champion_embed = nn.Embedding(num_champions, CHAMPION_EMBEDDING_DIM)
self.keystone_embed = nn.Embedding(num_keystones, KEYSTONE_EMBEDDING_DIM)
self.spell_embed = nn.Embedding(num_spells, SPELL_EMBEDDING_DIM)
self.role_embed = nn.Embedding(5, ROLE_EMBEDDING_DIM)
Where CHAMPION_EMBEDDING_DIM, KEYSTONE_EMBEDDING_DIM, SPELL_EMBEDDING_DIM, and ROLE_EMBEDDING_DIM are hyperparameters that can be tuned.
Late in the project, we decided to revisit embeddings but instead of using a random initialization, we generated an initial set of vectors using LLMs. Specifically, we engineered a latent space with each axis corresponding to a stat like tankiness, damage, utility, etc., then had a LLM reason and generate a vector for each champion corresponding to predicted attributes. Using this approach gave slightly better results than the randomized embedding, but more testing is needed to determine whether this improvement was due to noise or if it is actually viable.
Switching to a one-hot encoding with a 171-length vector (there are 171 unique champions) led to our best results with MLP.
Loss
Since our midterm report, the main changes to the MLP model are the use of one-hot encoding, deletion of previous attention mechanisms in favor of passing in matchup statistics, and a change to the loss function. Regarding loss, we augmented the loss with a MSE loss between predicted and actual gold graphs. The idea is to make an additional, more fine-grained signal, available to the model. After testing, we found that increasing the weight of the gold loss led to lower blue side bias but a lower accuracy.
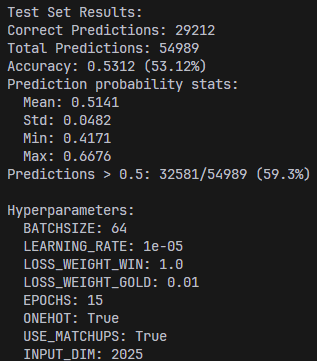
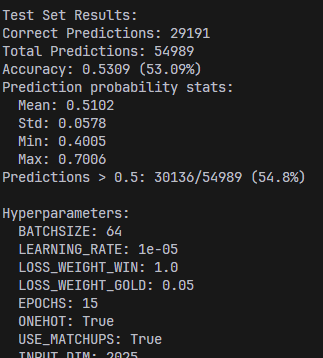
The second image has a higher gold weight, resulting in lower accuracy but less blue side bias
XGBoost
We implemented XGBoost as our second model because it is feature friendly, relatively robust to tabular inputs, and has overfitting control. It also yields feature importance graph which are useful for analysis. The configuration code is shown below:
model = XGBClassifier(
tree_method="hist",
max_depth=6,
learning_rate=0.01,
n_estimators=1000,
subsample=0.8,
colsample_bytree=0.8,
reg_lambda=1.0,
reg_alpha=0.1,
)
In the parameter setting, we use subsample and colsample_bytree to add some randomness to avoid overfitting. In addition, regularizations term(reg_lambda and reg_alpha) are used to ignore unimportant features or noisy matchup winrates that don’t generalize well.
XGBoost does not require one-hot encoding or embedding layers, this reduces the complexity of feature engineering, as XGBoost can naturally handle categorical features (such as champion and role) through its tree-splitting mechanism. As a result, we could just extract features from the JSONL file and used them for training.
Our model is trained on five key features—champion, rune, spell, role, and matchup statistics, using a training set of 1.2 million samples and evaluated on a test set of 100k samples.
Random Forest
We implemented Random Forest as our third model because of its ability to take in the raw IDs of champion/spell/rune/role without any need for embeddings. Also, it utilizes bagging and random feature subsets which help to improve generalization and assists in preventing overfitting. Additionaly, it naturally provides feature importance estimates, which makes it a strong baseline model and enables itself for feeding into another model potentially.
best_params = {
"n_estimators": 200,
"max_depth": 10,
"min_samples_split": 10,
"min_samples_leaf": 1,
"max_features": "log2"
}
train_rf_with_best_params(
matches=matches,
best_params=best_params,
output_model_path="rf_model_final.pkl",
test_size=0.2,
random_state=42,
test_jsonl_path="data/cleanmatches2.jsonl"
)
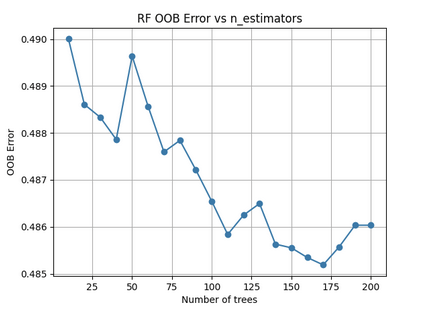

We added regularization (max_depth=12, min_samples_split=10, min_samples_leaf=5, max_features=”sqrt”), which showed us that around 150 trees is optimal here. We cap our trees’ potential complexity and force more splits to see fewer features and more samples. This reduced overfitting and improved generalization by giving us train accuracy of 77.4% and test accuracy of 52.3%. We also did a hyperparameter sweep to see which combination gave the best accuracy. The top five parameter sets all achieved around 52.3% test accuracy as shown in the image above.
This model, like XGBoost, is trained on five key features—champion, rune, spell, role, and matchup statistics, using a training set of 1.2 million samples and evaluated on a test set of 100k samples.
Results and Discussion
MLP
The best results for the MLP model are presented below.
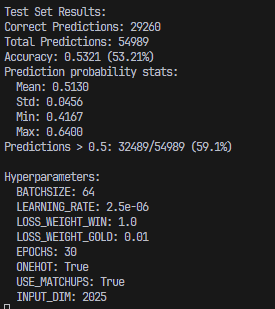
Additionally, a simplified version of the model taking in only champions was created for a web app. The web app mainly uses a simplified model due to the tediousness of selecting runes and summoner spells for 10 champions, each game. The best results for the simplified MLP model (for the web app) are presented below.
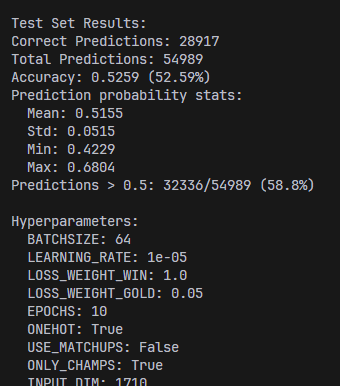
XGBoost
The results for XGBoost are presented below.
Prediction distribution (on test set): Counter({1: 62288, 0: 47708})
Train Accuracy: 0.575
Test Accuracy: 0.535
Need to mention that to reduce bias, we used separate datasets for training and testing. On the 100k test set, the model predicted the blue team to win in 62,288 games and the red team in 47,708 games. The test accuracy is 0.535, while the training accuracy is 0.575, which is acceptable.
From the feature importance graph generated, it can be seen that matchup statistics plays the most important role in prediction, which makes sense since counterpicks between champions do exist and are critical.
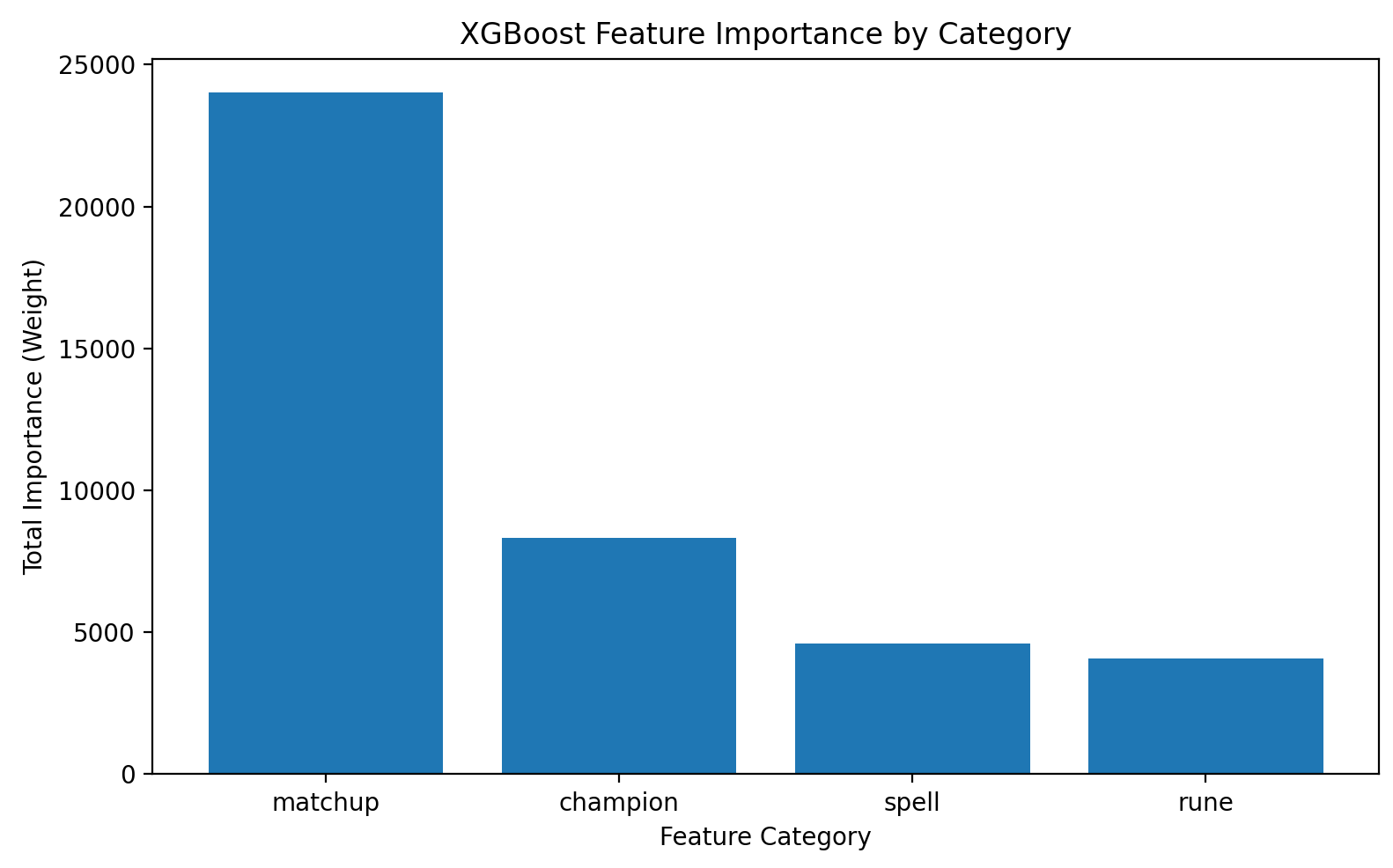
XGBoost offers several advantages in our task: it is feature-friendly, handles tabular data efficiently, and supports feature importance analysis. However, it also has some limitations, unlike neural networks, it can not learn complex feature interactions automatically through embeddings or hidden layers, which may limit its ability to capture champion-role relationships. Moreover, it does not model sequential or time-dependent information, which is relevant when predicting win rates across multiple in-game time period.
To further improve performance, we could incorporate early in-game data as additional features for prediction. In games like League of Legends, player skill is a critical factor, and early-game statistics strongly reflect this aspect.
Random Forest
Our Random Forest results are shown below.
Loaded 1235341 matches
[RF] train acc: 0.577, test acc: 0.534
We found very similar results to our XGBoost here and we applied the same method for testing with a separate 100k test set to reduce our bias. Our training accuracy was 57.7% and our testing accuracy was 53.4%.
We also saw similar feature importance graphs here, where matchup statistics is by far the most dominant feature for prediction, which makes sense from our anecdotal experience as we use counterpicks as the number one indicator for winning ourselves. There is also a lot of hidden information in these winrates that captures vital information that could be hard to learn with neural networks.
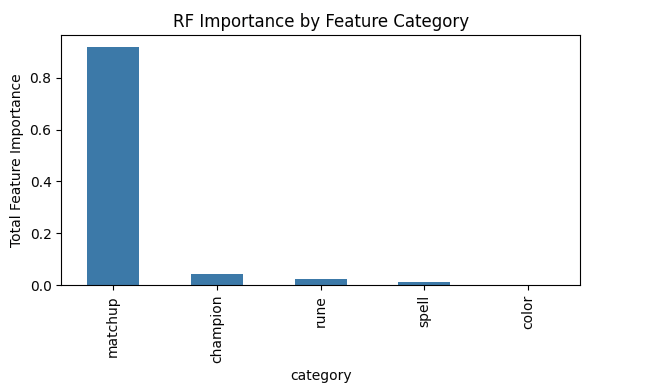
Our Random Forest excels on the high-dimensional IDs without embeddings and gives us the importance rankings, but still overfits without tuning and it likely struggles to capture time dependent dynamics. Future steps could include integrating early game and temporal features or combining our random forest model with other sequence models to look at winrates as matches progress.
Conclusion
In this project, we designed and tested 3 models to predict winrate of league games from intitial game features. Building on the techniques in our literature review, we additionally tried novel techniques such passing in computed matchup data and champion embeddings.
We produced a top accuracy of 53.5% using XGBoost, which also happened to be the least biased. This result confirms that the model has learned some patterns, and also reinforces that game outcome depends heavily on player skill and in-game events rather than initial game state.
Lastly, we produced a web-app that locally hosts a model to serve as an interactive visualization tool.
Contribution Table
| Name | Final Contributions |
|---|---|
| Nicholas | Frontend Implementation, Data Processing, MLP |
| Yuchen | Implemented XGBoost and its corresponding visualizations |
| Owen | Implemented Random Forest and its corresponding visualizations |
| Eric | Worked on MLP and embedding |
| Arya | Dataloader |
| Richard | TA |