4641-project
Midterm Checkpoint
Introduction/Background:
Humans are quite good at pattern recognition, but in some cases, like cancer cell identification or high frequency trading, machines can pick up on subtle patterns invisible to most humans. We hypothesize that this applies to win ratio predictions in MOBA games, specifically League of Legends. League of Legends is a competitive multiplayer game where teams of 5 players choose unique champions and compete to destroy the enemy nexus.
Existing work in this field revolves around computing win probability over the course of the match based on real time data (gold leads, objectives, etc.) [1] [2]. However, being able to predict game outcomes based solely on pregame data, such as player and champion trends, can inform players of how to approach the match to maximize chances of winning. In addition, the ability to predict game outcomes can be used to analyze the fairness of matchmaking and inform better matchmaking algorithms.
The primary dataset will be the Riot games API, which will allow us to request a wide variety of relevant data.
Problem Definition
Given only pre-game information available at match start, our goal is to generate a winrate graph over time for a given match. Formally, we want to model \(\mathbb{P}(\text{blue win} \mid \text{pre-game features, match duration} \geq t)\)for some time \(t\). It suffices to only model blue win since League is zero sum.
Methods
Data Collection
Collecting data for the model turned out to be a somewhat challenging process. We needed to generate a dataset of matches, but unfortunately the Riot API does not directly provide a way to get recent matches. Instead, the API provides a list of recent matches for each player, so our dataset generation had to be split into two parts:
Part 1 (Match Seeding)
- Query the Riot API for a list of players
- For each player, get their 20 most recent matches (returned as IDs), store them in the database, and add the matches to a queue.
- While the queue is not empty,
- Pop a matchid from the queue,
- Call the Riot API to get the corresponding match data for that match.
- For each of the 10 players in that match, add their 20 most recent matches to the database and the queue.
Since the queue never becomes empty due to the high branching factor, this program is manually stopped by the user once a sufficient number of matches have been seeded.
Part 2 (Match Cleaning)
- Query the database for uncleaned match_ids
- For each match_id, query the Riot API for the corresponding match data
- Clean and extract the useful parts of the data and store in the database.
- Repeat steps 1-3 until all seeded matches have been processed.
The Riot API has a rate limit of about 1 request a second. Since each player has 20 recent matches, the seeder adds about 20 matches to the database with 1 API request and was thus able to process around 200k matches in just a few hours. For the match cleaner, each match required a distinct API call, so processing 200k matches required a total of 55 hours. While this may be feasible for now, we plan on increasing the dataset size, so we used AWS to implement a scalable architecture.
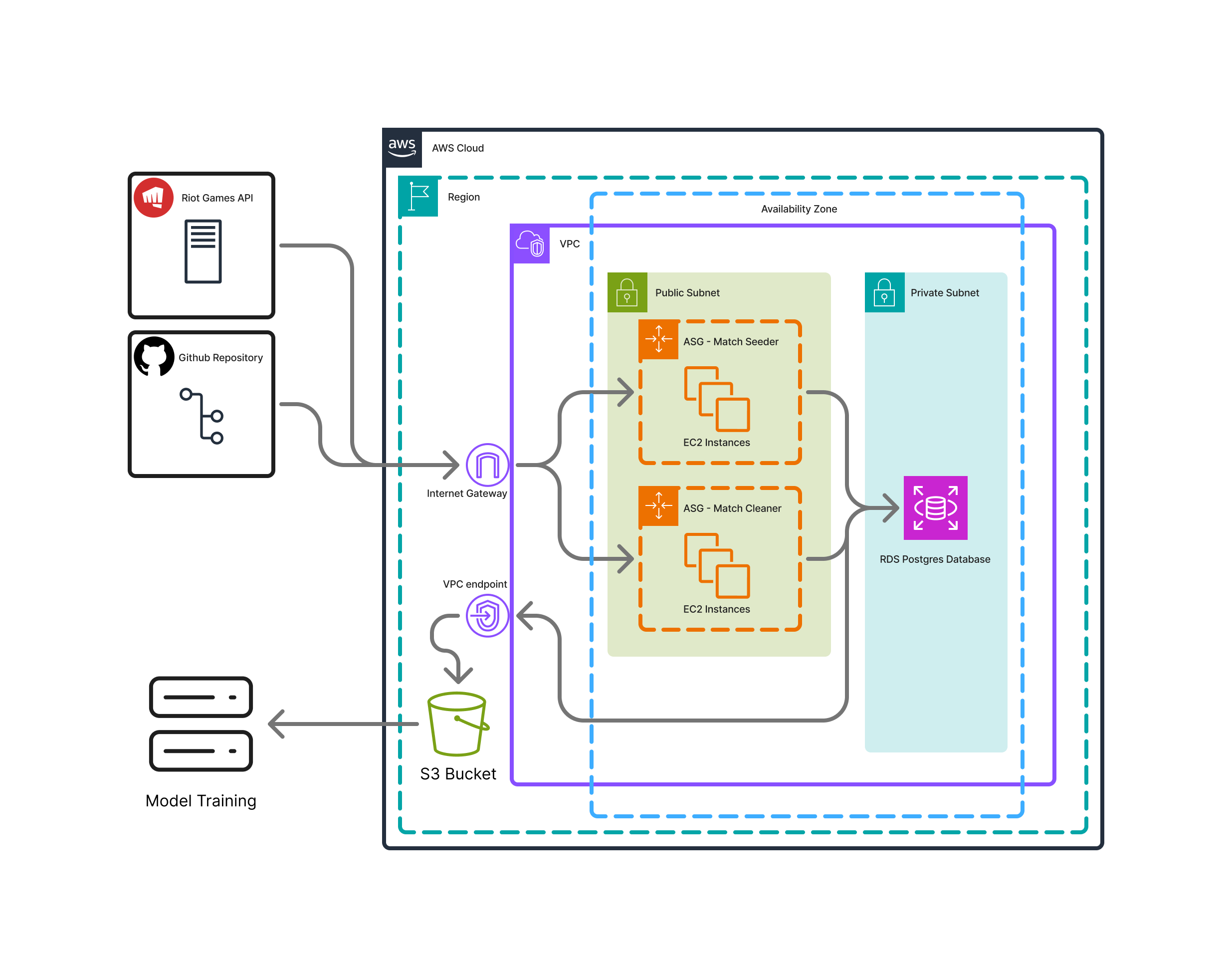
For those unfamiliar with AWS: We setup remote computers to make API calls concurrently. With 3 API keys provided by various team members, we were able to cut down the 55 hours to 18. A PostgreSQL database stored the match data, and using SFTP we dumped the database to a zip file and transferred it to a local computer for training.
For those familiar AWS: 2 ASGs were setup to easy scale the Match Seeders and Match Cleaners. EC2s were launched from an AMI that contained a clone of the Github repo, and systemctl services to easily start/stop scripts on the repo (which were started/stopped with an SSM command).
Getting concurrency to work with the database required adding a “batch_number” column to each match entry, which was a random integer \(\in [1,3]\). Each match cleaner only selected matches with a specific batch number, ensuring data was never read/written to more than once.
Finally to transfer the data, the database was dumped to an S3 bucket as a tarball, and then SFTPed to a local computer.
In terms of limitations, the EC2s were setup on a single public subnet on a single AZ. This was done mainly for convenience and ease-of-setup purposes, but for the final report we may change this setup to be more available.
Data Cleaning
A limited amount of data cleaning was performed by the Match Cleaners, namely eliminating games that were detected to have cheaters, and only storing useful information. Detecting more nuanced forms of noise, namely “griefing”, wherein a player intentionally plays bad to force a loss, is a problem that even Riot Games has been unable to solve. The cues for a griefer are often highly subtle, as it can take the form of a player having bad positioning, forcing bad plays, or other actions that are often not directly represented by the statistics. However these datapoints can be detrimental to the model training, so some effort will be made into cleaning at least a sizeable portion of these matches for the final submission.
Other Limitations and Future Plans
As discussed later on, this problem is highly nonlinear and noisy, so augmenting the model with extra data will likely be extremely beneficial. For example, League of Legends as a game is strongly influenced by “matchups”, which are the interactions between 2 opposing champions. Riot does not provide winrates or any data about specific matchups, but there exist 3rd party websites which do. Our next step is to scrape these website for matchup data, and add the corresponding data to the match entries.
Additionally, our dataset is somewhat small for a highly dimension model such as this, so we hope to generate a dataset at least 10x in size. Fortunately all the infrastructure to support generating such a dataset has been setup already, so this should be fairly simple and just a matter of time.
Supervised ML Algorithms/Models Implemented
We implemented a simple multi-layer perceptron as our first model. We chose MLP primarily for its simplicity; and to use as a baseline. The configuration code is shown below:
class MLP(nn.Module):
def __init__(self):
super().__init__()
self.embedding = HybridEmbedding()
embedding_output_dim = 1760 # 10 players * 176 features per player
self.mlp = nn.Sequential(
nn.Linear(embedding_output_dim, 512),
nn.ReLU(),
nn.Linear(512, 256),
nn.ReLU(),
nn.Linear(256, 128),
nn.ReLU(),
nn.Linear(128, 6),
nn.Sigmoid()
)
def forward(self, champions, keystones, spells, roles):
embedded_features = self.embedding(champions, keystones, spells, roles)
return self.mlp(embedded_features)
The layer sizes were chose somewhat arbitarily and the last Sigmoid layer is used to get our predictions within a 0-1 range.
Note, the first step involves an embedding layer in which internal ids for champions, runes, spells, and roles are mapped to a latent space with nn.Embedding. This is initially randomized and is learned through training. The embedding layers are as follows:
self.champion_embed = nn.Embedding(num_champions, 64)
self.keystone_embed = nn.Embedding(num_keystones, 16)
self.spell_embed = nn.Embedding(num_spells, 8)
self.role_embed = nn.Embedding(5, 8)
self.champ_role_embed = nn.Embedding(num_champions * 5, 16)
self.champion_attention = nn.MultiheadAttention(64, 8, batch_first=True)
We combined champion and roles together for an additional feature due to significance of the relationship between champion and role. While the model may have been able to learn this relationship based on feature positions, we made a deliberate design choice to engineer an explicit feature. Similarly, to encourage the model to learn inter and intra champion relationships, we added an attention mechanism.
The loss function we used was binary cross entropy loss; but due to the nature of our ground truth and predictions, we had to modify it. Specifically, we predict outcomes at 6 time buckets, but the ground truth only has a label at 1 time bucket. Thus, the loss function simply picks the closest time bucket and uses the corresponding prediction with the ground truth label to compute BCE loss.
In training, we typically used larger batch sizes from 64 to 256 and experimented with varying learning rates. We used various optimizers such as Adam and SGD.
Results and Discussion
Our initial attempts to train the MLP model have yielded disappointing results. The model’s loss improves on training data but actually increases on validation data. This is due to two reasons:
- Overfitting to the training data
- The model starts with predictions near 0.5, then drifts to extreme predictions near 0 and 1 which increase validation loss more than random guessing near the mean.
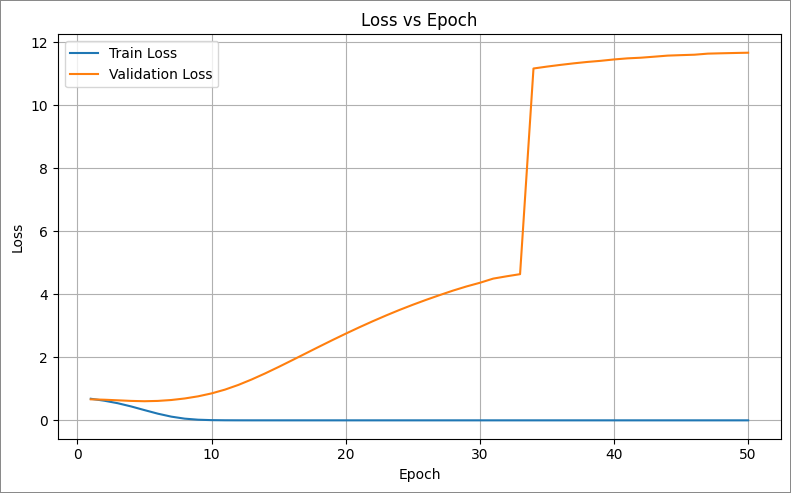
These results are consistent across different batch sizes and learning rates
Moreover, the binary feedback seems to be too abstract of a learning signal; it only tells the model whether a set of pre-game features ultimately led to a win or a loss. Because this signal doesn’t provide any feedback on why that outcome occurred or which pre-game interactions contributed, the patterns that humans intuitively use to predict match outcomes—such as how specific characters interact—cannot be effectively learned by our model. The model struggles to develop the internal representations that capture these nuanced characteristics.
We will discuss how to address these issues in the next section.
Going Forward
The poor results indicate fundamental flaws in our approach and architecture. Currently, we hypothesize the biggest issue to be the inability of the model to learn from the noisy and abstract signal (binary win/loss). Going forward, we will address this in the following ways:
- Incremental training. We hope that our embedding layer at the forefront of the model can capture semantic meaning. For instance, we wish for tanky champions to have a similar direction, and for different axis or directions to represent certain characteristics. Our current training loop and loss function do not train the embedding layer well enough, and without an embedding with semantic meaning, the model cannot recognize patterns between the various inputs. Therefore, we will train the embedding seperately with a different dataset, then eventually fine tune it.
- Better loss function. We will scrape additional data from the Riot API, notably gold graphs, to improve the loss function. Currently, we use a binary cross entropy loss but we can only compare one prediction with the ground truth since the ground truth is a binary win/loss + timestamp. With additional data like gold graphs, we can give better feedback to the model.
- Explainability. Just as CNNs have neurons like edge detectors, feature extractors, and neurons that capture semantic meaning, we wish for our model to exhibit the same explainability as this will guide model design choices. For example, we would like for some early neurons to capture AD/AP damage ratio, others to capture intra-team synergies and inter-team counters, and then later neurons to capture higher level features like early vs late game biases or general team composition strengths.
- Augmentation. As a human, we can make predictions on the outcome of a match primarily through experience and knowledge of how certain matchups and synergies go. Experienced players will have played thousands of matches and understand the early and late game strengths of each individual champion, and use reasoning to combine their understanding into a prediction. Our ML model has no understanding of each champion, their strengths, or their counters/synergies. Many of these statistics are available online though, and we plan to augment input data with these statistics, or train certain layers (akin to a backbone network) on these signals.
- GANs. Due to the extremely noisy signal, it may be effective to generate artificial data based on high level statistics to get the model to a reasonable state, then fine tune the model on real data. We may look into GAN architectures as our model plays a similar role as a discriminator.
- Other model architectures. Our literature review found Random Forest and XGBoost to exhibit good results while MLP performs rather poorly. Thus, in future iterations, new model architectures may prove promising.
- Better prediction outcome. The model can easily achieve 50% accuracy by random guessing making randomized models perform quite well. In order to prevent the validation loss increase we see currently, it may be beneficial to force the model to predict binary 0 or 1 using thresholds. Alternatively, predicting in the range of -1 to 1 may yield better results and decrease bias.
Contribution Table
| Name | Midterm Contributions |
|---|---|
| Nicholas | Data Collection with Riot API and data preprocessing |
| Yuchen | Implemented the initial MLP and fixed README.md |
| Owen | Cleaned the data for data preprocessing and Gantt Chart |
| Eric | Worked on MLP, embedding, visualization, data preprocessing, model, and steps going forward |
| Arya | Designed and integrated the data loader and the results & discussion |
| Richard | TA |